
{kind=link}
Meta 於今(4/19)日宣布新一代 Llama 3 初始的兩個模型已可廣泛使用。此版本包含預訓練和指令微調的語言模型,其中的 8B (80 億) 和 70B (700 億) 參數,可支援更多元的使用情境。新一代 Llama 在多項產業指標上展現了卓越的成效,並提供許多新的功能,包括更精準的推理能力,是目前同業中最佳的開源模型。此外,延續 Meta 長期以來的開放創新模式,Llama 3 將釋出供社群運用。Meta 將全面引領新的 AI 技術創新浪潮,從應用程式、開發人員工具、評估,再到優化推理能力等,並鼓勵開發者開始建立專屬的內容,給予更多回饋與建議。

Llama 3 的目標
Meta 希望透過建立與目前專有模型並駕齊驅的最佳開放模型 Llama 3 ,回應開發人員的回饋,並提高 Llama 3 的整體實用性,同時持續領導負責任地使用並部署大型語言模型。Meta 秉持及早釋出與頻繁更新的開源精神,讓社群搶先試驗這些仍在開發階段的模型。今日所推出的以文字為基礎的模型為 Llama 3 系列的第一波模型。Meta 期待讓 Llama 3 在近日具備多語言和多模態、有更長的上下文語境,並繼續提升推理和編寫程式碼等核心大型語言模型能力的整體表現。
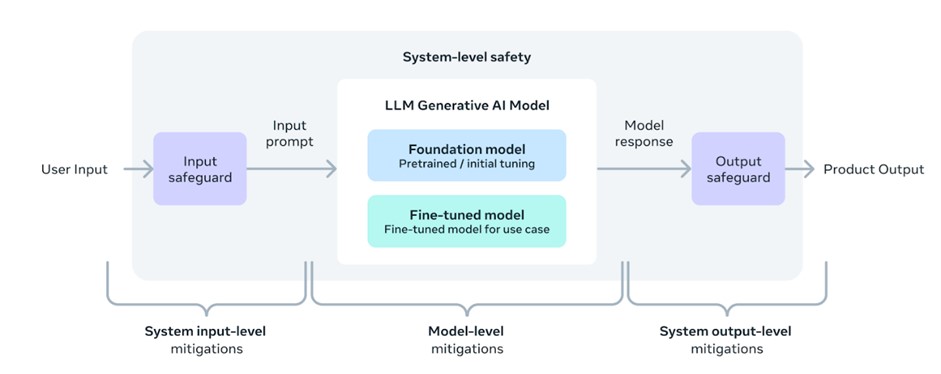
Meta 採用全新的架構以系統性的方式負責任地部署模型
Llama 3 卓越的效能
Llama 3 中全新 8B 和 70B 參數的模型,相較於 Llama 2 有大幅的進步,並為此規模的大型語言模型立下新標準。得益於預訓練與後訓練技術的進展,Meta 的預訓練和指令微調模型是目前 8B 及 70B 參數規模的最佳模型。Meta 在後訓練程序流程的改進大幅降低錯誤拒絕率(False Rejection Rate, FRR),改善一致性,並提升模型反應的多樣性。同時,在推理、程式碼生成和指令遵循等功能亦有顯著提升,讓 Llama 3 更易於操控。

歡迎加入我們的粉專與YouTube頻道隨時掌握科技脈動
https://www.facebook.com/Jazz-News-109538211346562
https://www.youtube.com/c/PapaJazz1
本文所有權為 Jazz
- 超帥限量必敗!海尼根首度攜手法國軍靴品牌PALLADIUM打造潮流包款 - 2024 年 5 月 2 日
- Google宣布:Gemini 應用程式與擴充功能正式支援繁體中文 - 2024 年 5 月 2 日
- SNOOPY粉絲別錯過!康寧餐具推出母親節主題活動有買一送一超值優惠 - 2024 年 4 月 30 日